Коллекции #
Обязательно к прочтению
- ArrayList - https://habr.com/ru/articles/128269/
- LinkedList - https://habr.com/ru/articles/127864/
- HashMap - https://habr.com/ru/articles/128017/
1. Расскажите как выглядит иерархия коллекций #
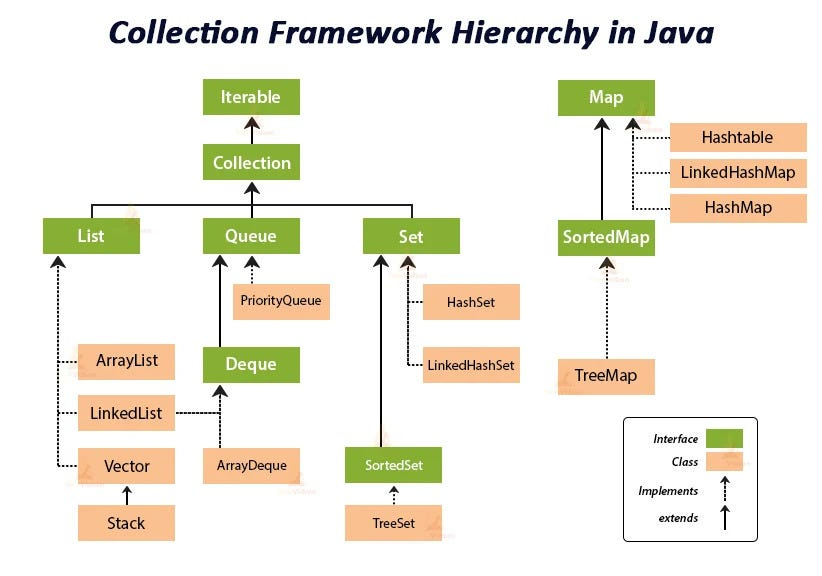
Collection и Map - два интерфейса, которые находятся на вершине иерархии JCF. Интерфейс Collection расширяют интерфейсы:
- List
- Queue
- Set
2. Что такое ArrayList? #
Это список, реализованный на основе динамически расширяемого массива. То есть под капотом буквально создается массив
3. ArrayList. Какая размерность массива по умолчанию? #
Capacity = 10
Можно ли задать начальную емкость/размер списка?
Да, через конструктор (List<String> list = new ArrayList<String>(15))
4. ArrayList. Что происходит под капотом при добавлении/удалении элемента в начало/середину/конец списка? #
Добавление в конец списка:
- Проверяется достаточно ли места для добавления нового элемента. Если достаточно, то переходим к п. 2, если нет:
- Создается новый массив размером в 1.5 раза больше
- Копируются все элементы из старого массива
- Новый элемент добавляется в конец
Добавление в начало/середину списка:
- Проверяется, достаточно ли места для добавления нового элемента. Если достаточно, переходим к п. 2, если нет:
- Создается новый массив размером в 1.5 раза больше
- Копируются все элементы из старого массива
- Все элементы, начиная с нужного индекса, сдвигаются на один вправо
- Элемент с нужным индексом перезаписывается новым значением
Описанные операции копирования и сдвига элементов осуществляются функцией System.arraycopy(). Т.е. в случае добавления в конец списка System.arraycopy() будет вызвана 0 или 1 раз, в случае добавления в середину — 1 или 2 раза.
Прим. В старых версиях Java (как минимум в 6-й, которую использует автор статей из верхушки текущей страницы) при недостатке места для добавления нового элемента создавался массив размером 1.5*старый_размер + 1
5. ArrayList - сложность операций #
ArrayList — это реализация динамического массива в Java. Основные характеристики производительности операций зависят от внутреннего устройства структуры данных
ArrayList. Какая скорость добавления элемента в начало/середину/конец списка?
| Место добавления | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Начало списка | O(n) | O(n) | Все элементы сдвигаются вправо для освобождения места. |
| Середина списка | O(n) | O(n) | Элементы после точки вставки сдвигаются вправо. |
| Конец списка | O(1) | O(n) | Амортизированная сложность O(1), но если массив переполняется, требуется перераспределение. |
ArrayList. Какая скорость удаления элемента в начале/середине/конце списка?
| Место удаления | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Начало списка | O(n) | O(n) | Все элементы сдвигаются влево для заполнения освободившегося места. |
| Середина списка | O(n) | O(n) | Элементы после удалённого элемента сдвигаются влево. |
| Конец списка | O(1) | O(1) | Удаление последнего элемента происходит мгновенно без необходимости сдвигать элементы. |
ArrayList. Какая скорость доступа по индексу и значению?
| Операция | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Доступ по индексу | O(1) | O(1) | Прямой доступ к элементам массива за константное время благодаря индексации. |
| Поиск по значению | O(n) | O(n) | Линейный поиск, так как элементы не отсортированы и требуется перебор всех значений. |
Сложность по времени ArrayList.contains()
Время выполнения: O(n), где n — количество элементов. contains() выполняет линейный поиск, сравнивая элементы по порядку.
6. Что такое LinkedList? #
Классический двусвязный список, основанный на объектах с ссылками между ними. Реализует интерфейсы List и Deque. Данные хранятся в объектах типа Node
7. LinkedList. Что происходит под капотом при добавлении/удалении элемента в начало/середину/конец списка? #
При создании LinkedList-а, у нас создается псевдо элемент - Header в котором хранятся next и prev, которые пока указывают сами на себя. После добавления элемента, ссылки next и prev у каждого объекта будут указывать на предыдущий и следующий.
8. LinkedList - сложность операций #
В LinkedList элементы фактически представляют собой звенья одной цепи. У каждого элемента помимо тех данных, которые он хранит, имеется ссылка на предыдущий и следующий элемент. По этим ссылкам можно переходить от одного элемента к другому.
LinkedList. Какая скорость добавления элемента в начало/середину/конец списка?
| Место добавления | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Начало списка | O(1) | O(1) | Новый узел добавляется перед первым, переназначаются ссылки. |
| Середина списка | O(n) | O(n) | Требуется пройти список до нужного узла, после чего выполняется вставка. |
| Конец списка | O(1) | O(1) | Новый узел добавляется после последнего, переназначаются ссылки. |
LinkedList. Какая скорость удаления элемента в начале/середине/конце списка?
| Место удаления | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Начало списка | O(1) | O(1) | Удаление первого узла выполняется мгновенно, ссылки переназначаются. |
| Середина списка | O(n) | O(n) | Требуется пройти список до нужного узла, после чего выполняется удаление. |
| Конец списка | O(1) | O(1) | Удаление последнего узла выполняется мгновенно, если есть доступ к последнему элементу. |
LinkedList. Какая скорость доступа по индексу и значению
| Тип доступа | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
| Доступ по первому элементу | O(1) | O(1) | Первый элемент хранится в ссылке head, доступ к нему мгновенный. |
| Доступ по последнему элементу | O(1) | O(1) | Последний элемент хранится в ссылке tail, доступ к нему мгновенный. |
| Доступ по индексу | O(n) | O(n) | Линейный обход от начала или конца до нужного индекса. |
| Доступ по значению | O(n) | O(n) | Линейный перебор всех элементов до нахождения искомого значения. |
9. ArrayList vs LinkedList #
| Критерий | ArrayList | LinkedList |
|---|---|---|
| Расположение в памяти | Последовательные блоки памяти (массив). | Элементы связаны через указатели. |
| Добавление в конец | O(1) (если есть место) или O(n) (при расширении). | O(1). |
| Добавление в начало | O(n) (сдвиг всех элементов). | O(1). |
| Добавление в середину | O(n) (сдвиг элементов). | O(n) (поиск нужной позиции + изменение ссылок). |
| Удаление элемента | O(n) (сдвиг оставшихся элементов). | O(n) (поиск) или O(1) (если указатель известен). |
| Поиск по индексу | O(1). | O(n) (идём по ссылкам). |
| Поиск по значению | O(n). | O(n). |
| Память | Использует меньше памяти, т.к. хранит только данные. | Использует больше памяти, т.к. хранит ссылки. |
Где какой использовать?
ArrayList следует использовать, когда в приоритете доступ по индексу, так как эти операции выполняются за константное время. Добавление в конец списка в среднем тоже выполняется за константное время. Кроме того в ArrayList нет дополнительных расходов на хранение связки между элементами. Минусы в скорости вставки/удаления элементов находящихся не в конце списка, так как при этой операции все элементы правее добавляемого/удаляемого сдвигаются.
LinkedList удобен когда важнее быстродействие операций вставки/удаления, которые в LinkedList выполняются за константное время. Операции доступа по индексу производятся перебором с начала или конца (смотря что ближе) до нужного элемента. Дополнительные затраты на хранение связки между элементами.
Одним словом - если часто вставляете/удаляете - выбирайте в пользу LinkedList, в противном случае ArrayList
Преподаватель и сотрудник компании JetBrains Тагир Фаридович Валеев на своих лекциях утверждает, что НЕ стоит использовать
LinkedList, т.к. он не оптимизирован. Все задачи можно решить с такой же скоростью или быстрее используяArrayList/ArrayDeque
10. Какая скорость вставки в ArrayList и LinkedList #
ArrayList:
- Сложность: O(n), так как требуется сдвиг элементов, чтобы освободить место для нового элемента.
- Подходит, если вставки происходят редко.
LinkedList:
- Сложность: O(n), так как требуется найти позицию для вставки (линейный поиск) и изменить ссылки.
- Лучше подходит для частых операций вставки, особенно в начале / конце списка.
11. Что такое TreeMap? #
Класс в Java, который реализует интерфейс NavigableMap, который в свою очередь наследуется от SortedMap. Представляет собой ассоциативный массив, где ключи отсортированы в естественном порядке (или по заданному компаратору).
Единственная коллекция, которая не использует equals() и hashCode().
Основана на красно-черных деревьях
12. TreeMap - сложность операций #
О(log n) (т.к каждый раз отметается половина)
13. Внутреннее устройство TreeMap #
Древовидная структура: под капотом TreeMap использует структуру данных, которая называется красно-чёрное дерево.
14. Что такое HashMap? #
Ассоциативный массив, хранит пары “ключ-значение”. Ключ-уникальный, значение-может повторяться. Каждая ячейка массива - бакет(корзина), хранящий в себе односвязный список узлов. Если у односвязного списка node больше 8 элементов (коллизии), он превращается в красно-чёрное дерево, обратно - если количество элементов в бакете уменьшилось до 6. Может содержать один ключ null и любое количество значений null. Не отсортирован и не упорядочен
15. Внутреннее устройство HashMap #
В HashMap бакет — это элемент массива, в котором хранятся записи (ключ-значение). Если у нескольких ключей совпадает хеш, их записи попадают в один бакет, где организуются в виде связного списка или сбалансированного дерева (в зависимости от Java версии).
Сколько изначально бакетов создается?
По умолчанию - 16
В каком случае количество бакетов увеличивается?
Если массив бакетов заполнен на 75 процентов - создается х2 от начального размера
Чтобы определить номер бакета есть формула. Какие в ней переменные?
bucketIndex = (hash & (capacity - 1));
hash— хэш-код ключа, который возвращает методkey.hashCode().capacity— текущая ёмкость таблицы (всегда степень двойки, например, 16, 32).bucketIndex— индекс бакета, в котором будет храниться элемент.
Операция побитового & (AND) используется вместо %, так как она быстрее и эффективнее для степеней двойки.
16. Что такое бакет? Внутреннее устройство бакета #
🗂️ Что такое бакет в HashMap?
Бакет — это элемент внутренней структуры HashMap, который используется для хранения пар ключ-значение.
Когда ты добавляешь элемент в HashMap, хеш-функция вычисляет хеш-код ключа, и на его основе определяется индекс бакета, куда будет помещён элемент.
⚙️ Внутреннее устройство HashMap и бакетов
- Хеш-функция: преобразует ключ в хеш-код.
- Массив бакетов: каждый элемент массива — это бакет.
- Бакет: может быть пустым или содержать одну или несколько пар ключ-значение.
🧱 Структура бакета:
В Java (например), каждый бакет — это связный список или дерево (если слишком много коллизий).
HashMap (массив бакетов)
│
├── Bucket[0] → null
├── Bucket[1] → Entry(key1, value1) → Entry(key2, value2)
├── Bucket[2] → Entry(key3, value3)
└── ...
Если два ключа дают одинаковый хеш и индекс, они попадают в один бакет — это называется коллизией.
🌳 Когда бакет превращается в дерево?
В Java 8 и выше, если количество элементов в одном бакете превышает порог (обычно 8), связный список превращается в красно-чёрное дерево для ускорения поиска.
Bucket[5] → Red-Black Tree
├── Entry(keyA, valueA)
├── Entry(keyB, valueB)
└── ...
📊 Пример на Java:
Map<String, String> map = new HashMap<>();
map.put("apple", "green");
map.put("banana", "yellow");
"apple"→ хеш-код → индекс бакета → вставка в бакет"banana"→ другой хеш → другой бакет
🧠 Итог:
| Термин | Значение |
|---|---|
| Бакет | Ячейка массива, куда попадают элементы с одинаковым хеш-индексом |
| Коллизия | Ситуация, когда разные ключи попадают в один бакет |
| Entry | Объект, содержащий ключ и значение |
| Дерево в бакете | Оптимизация при большом числе коллизий |
17. HashMap - сложность операций #
| Операция | Средняя сложность | Худшая сложность | Пояснение |
|---|---|---|---|
Добавление (put) | O(1) | O(n) | В среднем: хеш-функция вычисляет индекс за константное время. В худшем случае — при множестве коллизий — все элементы хранятся в одной корзине как связный список или дерево (O(n)). |
Удаление (remove) | O(1) | O(n) | Удаление элемента по ключу быстрое в среднем. При множестве коллизий потребуется обход корзины. |
Поиск (get) | O(1) | O(n) | В среднем: доступ по хешу за константное время. В худшем случае — линейный обход корзины. |
Проверка наличия (containsKey / containsValue) | O(1) / O(n) | O(n) | Проверка ключа быстрая в среднем (O(1)), для значений требуется полный перебор (O(n)). |
| Итерация по элементам | O(n) | O(n) | Обход всех элементов требует линейное время, так как необходимо пройти все корзины. |
18. Процесс добавления объекта в HashMap #
- Вычисляем хеш-код ключа и бакет, в который будет добавлен новый элемент
- Если бакет пустой — просто добавляем элемент, если нет:
- идем по ключам элементов связного списка (или TreeMap) и сравниваем с ключом добавляемого элемента по хеш-коду и
equals() - если ключи равны — перезаписываем значение по этому ключу, если нет — переходим к следующему элементу
- если не нашли ключ добавляемого элемента (равный и по хеш-коду, и по
equals()) — добавляем этот элемент в конец связного списка (или в TreeMap)
- идем по ключам элементов связного списка (или TreeMap) и сравниваем с ключом добавляемого элемента по хеш-коду и
19. Будет ли работать HashMap, если все добавляемые ключи будут иметь одинаковый hashCode()? #
Да, будет, но в этом случае HashMap вырождается в связный список и теряет свои преимущества
20. Ключи в HashMap #
Почему предпочтительно использовать в качестве ключа immutable объект?
Потому что, если изменить объект на котором основан ключ, то у него поменяется хеш-код найти элемент в HashMap-е не получится. Именно поэтому предпочтительно использовать immutable объекты (например String)
HashMap. Собственный объект в качестве ключа
Для своего класса в качестве ключа нужен hashCode/equals
Почему строка является популярным ключом в HashMap?
- Иммутабельность (неизменяемость)
- Хорошая реализация методов
hashCode()иequals()
21. Могу положить в HashMap или TreeMap элемент с ключом null? #
| Map | Поддержка null-ключей | Примечания |
|---|---|---|
| HashMap | Да | null хранится в специальном слоте; повторная вставка перезапишет значение |
| TreeMap (по умолчанию) | Нет | Бросает NullPointerException при попытке вставить null |
| TreeMap с компаратором | Да | Компаратор должен поддерживать null, например Comparator.nullsFirst() или nullsLast() |
22. Что такое HashSet? #
HashSet — коллекция, не содержащая в себе дубликатов
23. Как HashSet связан с HashMap? #
HashSet использует HashMap для хранения элементов
24. Внутреннее устройство HashSet #
Сколько изначально бакетов создается?
По умолчанию создается - 16
В каком случае количество бакетов увеличивается
Если массив бакетов заполнен на 75 процентов - создается х2 от начального размера
25. HashSet - сложность операций #
О(1). Благодаря хеш-коду
26. Процесс добавления объекта в HashSet? #
HashSet использует HashMap под капотом: объекты являются ключами, а вместо значений используется константа-заглушка. Поэтому алгоритм добавления идентичен HashMap (элемент HashSet == ключ HashMap)
- Вычисляем хэш-код объекта и бакет, в который будем добавлять объект
- Если бакет пустой — объект добавляется в бакет, если нет:
- идем по ключам элементов связного списка (или TreeMap) и сравниваем с добавляемым объектом по хеш-коду и
equals() - если ключ элемента и объект равны — добавление игнорируется, если нет — переходим к следующему элементу
- если совпадений не найдено — добавляем объект в конец связного списка (или в TreeMap)
- идем по ключам элементов связного списка (или TreeMap) и сравниваем с добавляемым объектом по хеш-коду и
27. Будет ли работать HashSet, если все добавляемые элементы будут иметь одинаковый hashCode()? #
Да, будет, но его производительность ухудшится. Если все элементы имеют одинаковый хеш-код, они все будут размещены в одном бакете, что приведет к увеличению времени поиска
28. Что такое TreeSet? Внутреннее устройство #
🔹 Что такое TreeSet
- Коллекция, реализующая NavigableSet.
- Хранит элементы в отсортированном порядке.
- Дубликаты не допускаются.
- Основан на TreeMap.
🔹 Внутреннее устройство
- Под капотом используется TreeMap.
- TreeMap реализован через красно-чёрное дерево (self-balancing BST).
- Элементы — это ключи TreeMap, а значение = заглушка
PRESENT. - Вставка/удаление/поиск работают за O(log n).
🔹 Порядок элементов
- По умолчанию — natural ordering (
Comparable). - Можно задать свой порядок через Comparator (в конструкторе).
✅ Ключевые моменты
TreeSet= уникальные элементы + сортировка.- Под капотом →
TreeMap→ красно-чёрное дерево. - Все операции за O(log n).
- Удобен, если нужны отсортированные уникальные данные и быстрый поиск.
29. Что такое Queue? #
Queue - это интерфейс в Java, который представляет собой коллекцию элементов, работающую по принципу “первый вошел — первый вышел” (FIFO — First In, First Out).
30. Queue - сложность операций #
О(1)
31. Назовите главные реализации Queue? #
- LinkedList
- ArrayDeque
32. Что такое Deque? #
Deque (Double-Ended Queue) — это интерфейс в Java, который представляет собой очередь с двумя концами. Это означает, что элементы могут быть добавлены или удалены как с начала, так и с конца очереди. Таким образом, Deque может работать как очередь (FIFO) и как стек (LIFO).
Что значит двунаправленный?
Двунаправленный (или двухсторонний) в контексте Deque (Double-Ended Queue) означает, что элементы можно добавлять и удалять с обеих сторон очереди
33. Назовите главные реализации Deque? #
- LinkedList
- ArrayDeque (Double ended queue)
34. Dequeue - сложность операций #
О(1)
35. Какая коллекция реализует дисциплину обслуживания LIFO? FIFO? #
- ArrayDeque
36. HashMap vs TreeMap #
| Критерий | HashMap | TreeMap |
|---|---|---|
| Организация данных | Использует хэш-таблицу. | Использует красно-чёрное дерево. |
| Скорость доступа | O(1) для операций put/get. | O(log n) для операций put/get. |
| Порядок элементов | Элементы не упорядочены. | Элементы упорядочены по ключу. |
| Null ключи | Разрешает один null ключ. | Разрешает null ключи при передаче в конструктор соответствующего компаратора. По умолчанию не разрешает. |
| Использование | Для быстрого доступа к данным по ключу. | Для работы с упорядоченными данными. |
37. Как с собой связаны Iterable и foreach? #
Iterable— это интерфейс в Java, который определяет методiterator(). Он позволяет объекту предоставлять итератор для перебора его элементов.foreach— синтаксический сахар, который компилируется в использование итератора.
List<String> list = List.of("a", "b", "c");
// Использование foreach
for (String item : list) {
System.out.println(item);
}
// Как это работает под капотом:
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
System.out.println(item);
}
Вывод: foreach работает только с объектами, реализующими интерфейс Iterable, что обеспечивает возможность итерации.
Если мы будем итерироваться по Коллекции, мы можем удалить элемент?
Да, можно удалить элемент, но только с использованием итератора. Удаление через метод remove() коллекции при итерации приведёт к выбросу исключения ConcurrentModificationException.
Пример правильного удаления:
List<String> list = new ArrayList<>(List.of("a", "b", "c"));
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if ("b".equals(item)) {
iterator.remove(); // Удаление через итератор
}
}
System.out.println(list); // [a, c]
Удаление с использованием самого списка вызовет ошибку:
for (String item : list) {
if ("b".equals(item)) {
list.remove(item); // Ошибка: ConcurrentModificationException
}
}
Виды итераторов. Fail-Fast vs Fail-Safe
Fail-fast и fail-safe представляют две разные стратегии обработки ошибок, применяемые при работе с коллекциями в Java.
Итераторы fail-fast были добавлены в Java для обеспечения безопасности при работе с многопоточными коллекциями. Они основаны на модели “чистого” итератора, который не позволяет изменять список, пока он перебирается. Если во время перебора элементов коллекции происходит изменение структуры коллекции (например, добавление или удаление элемента), то итератор быстро завершает работу и выбрасывает исключение ConcurrentModificationException, чтобы предотвратить возможные ошибки в работе программы.
Итераторы fail-safe предоставляют альтернативный подход для работы с коллекциями. Они не используют блокировку при доступе к коллекции и не генерируют исключение ConcurrentModificationException при изменении коллекции во время итерации. Вместо этого они работают с копией коллекции, которая создается перед началом итерации, и гарантируют, что оригинальная коллекция не будет изменена никаким другим потоком во время итерации. Это обеспечивает более предсказуемое поведение итератора, но может приводить к неожиданному поведению в случае изменения коллекции другим потоком.
Таким образом, основная разница между fail-fast и fail-safe заключается в том, что fail-fast выбрасывает исключение при обнаружении изменений в коллекции, а fail-safe работает с копией коллекции, чтобы избежать конфликтов при изменении коллекции другим потоком. Решение о том, какой тип итератора использовать, зависит от требований проекта и особенностей работы с коллекцией. Если коллекция используется только в одном потоке или изменения происходят редко, то можно использовать итераторы fail-fast. Если же коллекция используется в многопоточной среде или изменения происходят часто, то следует использовать итераторы fail-safe.
| Критерий | Fail-Fast | Fail-Safe |
|---|---|---|
| Пример коллекций | ArrayList, HashSet, HashMap. | CopyOnWriteArrayList, ConcurrentHashMap. |
| Реакция на изменения | Бросает ConcurrentModificationException, если коллекция изменяется во время итерации. | Не выбрасывает исключений при изменениях. |
| Механизм работы | Проверяет изменения структуры коллекции (modCount). | Работает с копией коллекции или блокировками. |
| Производительность | Быстрее, так как не делает копий. | Медленнее, так как создаёт копии. |
38. Реализации интерфейса Map. Почему интерфейс Map выделен отдельно? #
Интерфейс Map выделен отдельно, так как он не является коллекцией в привычном смысле. Его предназначение — хранить пары “ключ-значение”, а не просто элементы.
| Реализация | Особенности |
|---|---|
HashMap | Быстрая, неупорядоченная, допускает null ключи. |
LinkedHashMap | Сохраняет порядок вставки элементов. |
TreeMap | Упорядочена по ключам, основана на красно-чёрном дереве. |
ConcurrentHashMap | Потокобезопасна, Fail-Safe. |
WeakHashMap | Использует слабые ссылки на ключи, полезна для кешей. |
39. Какую коллекцию использовать для уникальных отсортированных значений? #
TreeSet — хранит элементы в отсортированном порядке (по естественному порядку или по предоставленному компаратору) и гарантирует их уникальность.
40. HashTable - что это такое? #
HashTable — это реализация структуры данных хэш-таблицы в Java, которая позволяет хранить пары “ключ-значение”.
Она принадлежит пакету java.util и была введена в ранних версиях Java.
- Потокобезопасность: Методы синхронизированы, поэтому она подходит для многопоточных сред. Однако это снижает производительность по сравнению с несинхронизированными коллекциями, такими как
HashMap. - Запрещены
nullключи и значения: Попытка использоватьnullвызовет исключениеNullPointerException. - Наследие: Считается устаревшим, так как современные альтернативы, такие как
ConcurrentHashMap, более эффективны.
41. Arrays.asList() and List.of() #
| Метод | Arrays.asList() | List.of() |
|---|---|---|
| Модифицируемость | Возвращает изменяемый список. | Возвращает неизменяемый список (read-only). |
Допустимость null | Поддерживает элементы null. | Не допускает null элементы. |
| Тип возвращаемого списка | java.util.Arrays$ArrayList | ImmutableCollections.ListN |
| Проблемы | При добавлении/удалении элементов выбрасывает UnsupportedOperationException, так как связан с массивом. | Не поддерживает изменения, выбрасывает исключения при попытке модификации. |
| Использование | Для создания списка из массива с возможностью редактирования элементов. | Для создания небольшой неизменяемой коллекции. |
42. LinkedHashMap #
LinkedHashMap — это структура данных в Java, которая:
- хранит пары ключ–значение (как обычный
HashMap), - запоминает порядок добавления элементов или порядок использования,
- при этом работает почти так же быстро, как
HashMap(поиск, вставка — за O(1)).
🔹 Как работает
Внутри у него:
- Hash-таблица (как у
HashMap) → обеспечивает быстрый доступ по ключу. - Связный список → хранит порядок элементов.
👉 То есть каждый элемент знает не только «своё место» в хэш-таблице, но и ссылку на «соседей» (предыдущий и следующий элемент).
🔹 Порядок в LinkedHashMap
Есть два режима работы:
- По порядку вставки (insertion order)
Элементы возвращаются в том порядке, в котором были добавлены.
Пример: если ты добавил студентовИван,Мария,Олег— именно в таком порядке они и вернутся. - По порядку использования (access order)
Элементы переставляются в конец при каждом обращении.
Пример: если к студентуОлегобратились последним, то при обходе он будет выведен в конце.
👉 Этот режим часто используют для реализации LRU-кэша (Least Recently Used).
🔹 Отличие от других коллекций
HashMap— быстрый, но порядок непредсказуем.TreeMap— хранит отсортированные ключи (по алфавиту или по компаратору), но медленнее.LinkedHashMap— компромисс: быстрый какHashMap, но ещё и запоминает порядок.
🔹 Когда использовать
- Когда важен порядок элементов (например, вывод в том порядке, как пользователь вводил данные).
- Для кэширования, когда нужно выталкивать самые старые или редко используемые записи.
- Для хранения истории (например, последние открытые файлы в приложении).
43. Структуры данных. Какая сложность в дереве? #
| Операция | Обычное дерево | BST | Сбалансированное дерево | B-дерево |
|---|---|---|---|---|
| Поиск | O(n) | O(log n)/O(n) | O(log n) | O(log n) |
| Добавление | O(n) | O(log n)/O(n) | O(log n) | O(log n) |
| Удаление | O(n) | O(log n)/O(n) | O(log n) | O(log n) |